MangaUB
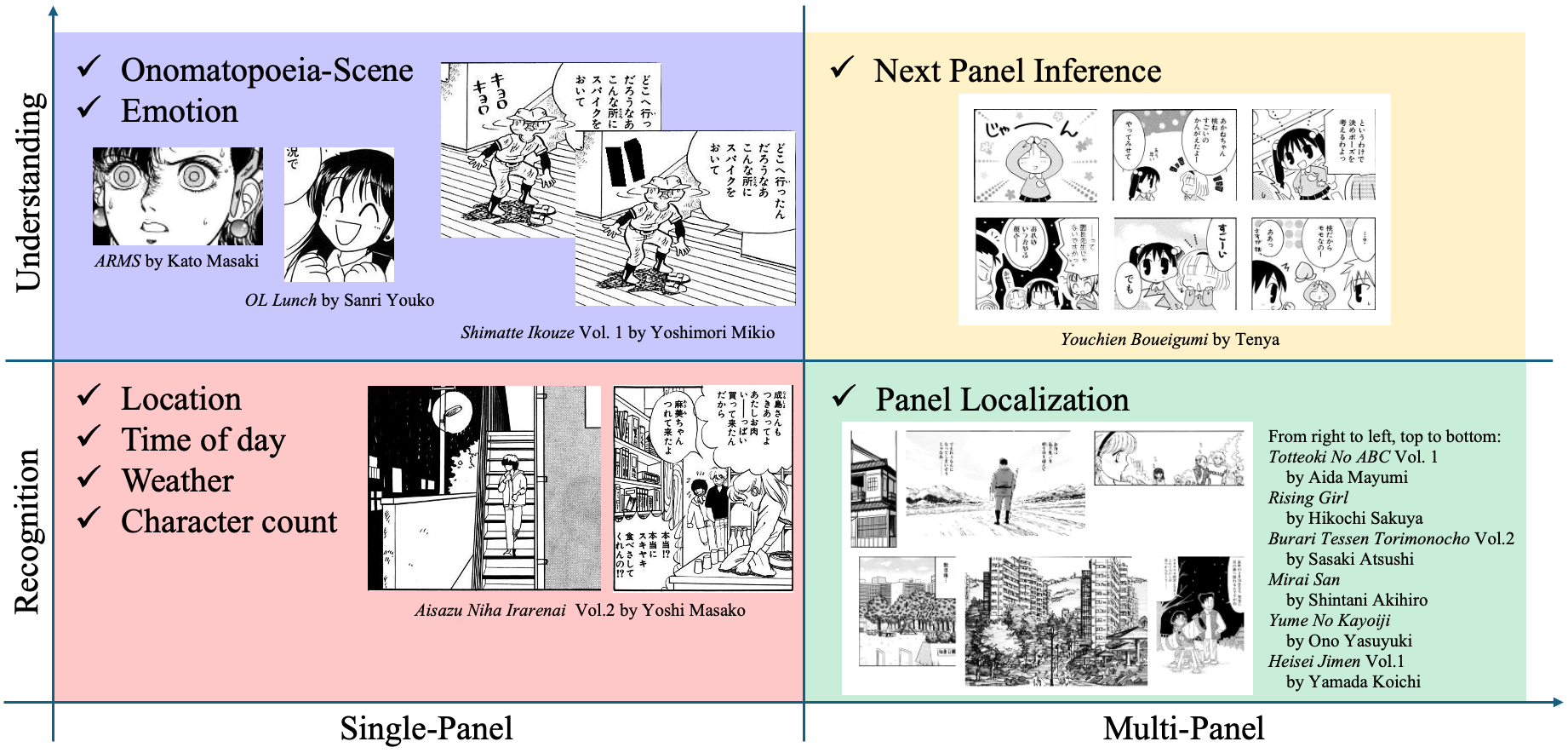
MangaUB は,Large Multimodal Model (Vision-Language Model) のための漫画を理解する能力を測るベンチマークです. Manga109およびその派生データセットに基づき,漫画の理解に関連した様々な難易度および内容のタスクを含んでいます. MangaUB は,単一のコマの内容の認識および理解だけでなく,複数のコマにまたがる情報の把握も評価できるように設計されており,漫画の理解に必要なモデルの様々な能力を詳細に分析することを可能にします.
内容:
- 質問数: 6,585
- プロンプト数: 18,179
タスク一覧:
-
Single-Panel Recognition:
- Location
- Time of Day
- Weather
- Character Count
-
Single-Panel Understanding:
- Onomatopoeia-Scene
- Emotion
-
Multi-Panel Recognition:
- Panel Localization
-
Multi-Panel Understanding:
- Next Panel Inference
関連リンク: